1. 负载均衡的作用
负载均衡(Load Balance LB),是通过单一的入口,使用某些算法,对用户流量进行分发,使用户请求合理的分配到多个服务器节点中的一种技术。
现代应用通常需要同时对大量用户提供服务,此时单台机器已经难以承担这些需求,因此需要使用多个节点同时为用户提供服务,但显然不能让用户记住多个域名甚至IP。LB位于用户与服务器集群之间,充当不可见的协调者,确保均等使用所有资源服务器。
2. DNS负载均衡
基于DNS的负载均衡比较简单,其原理是为一个域名配置多个A记录,这样当对域名进行请求时,就可以通过返回不同的域名进行流量的分配。
一种最常见的 DNS 负载平衡技术是循环 DNS。即在请求到来时,IP地址以循环方式轮换返回,请请求分散到关联的服务器上。
当然,也可以采用其他负载均衡策略,例如根据IP地址的地域等分配较劲的服务器。
3. 四层LB与七层LB
从形式上来说LB都可以分为两种:四层负载均衡和七层负载均衡。其中四层负载均衡的优势是性能高,七层负载均衡的优势是功能强。这里的四层、七层指的是OSI网络分层标准中的第四层传输层和第七层应用层。
3.1 四层LB
这里存在一个误解: **四层负载均衡并不是只工作在第四层传输层,事实上它们主要工作在二层(数据链路层)和三层(网络层)上。**根据OSI模型,当数据包到达第四层,其实已经到达了目标主机上,所以此时显然不存在什么流量转发了。四层负载均衡的真正含义是:这些工作模式的共同特点是都维持着同一个TCP连接。
数据链路层LB
数据链路层数据帧中包括有目的MAC地址和源MAC地址,数据链路层负载均衡所做的工作,是修改请求的数据帧中的 MAC 目标地址,让用户原本是发送给负载均衡器的请求的数据帧,被二层交换机根据新的 MAC 目标地址,转发到服务器集群中,对应的服务器的网卡上,这样真实服务器就获得了一个原本目标并不是发送给它的数据帧。
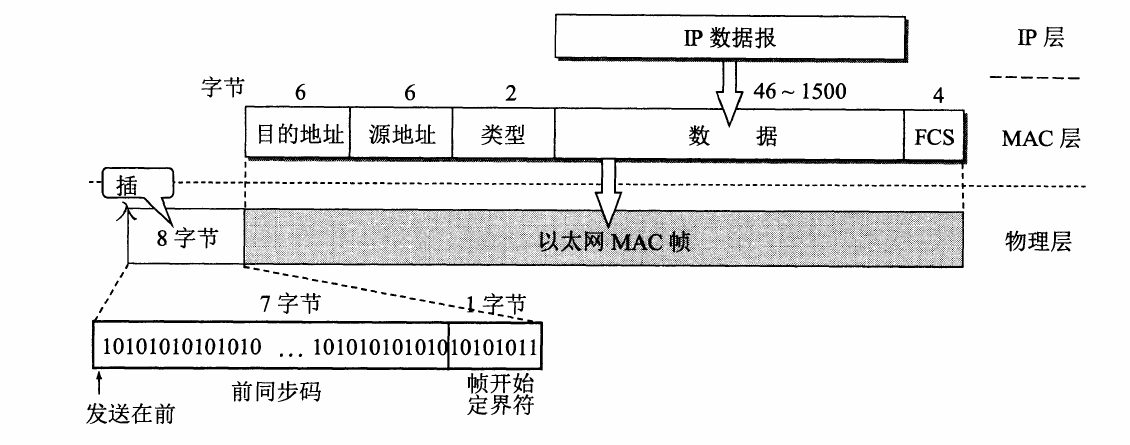
数据链路层的负载均衡只对目标MAC地址进行了修改,不涉及其他层次,因此对于更上层的网络层来说,数据是无变化的,这样网络层才能正常工作。
这是因为第三层的数据包,也就是 IP 数据包中,包含了源(客户端)和目标(均衡器)的 IP 地址,只有真实服务器保证自己的 IP 地址与数据包中的目标 IP 地址一致,这个数据包才能被正确处理。
所以,我们在使用这种负载均衡模式的时候,需要把真实物理服务器集群所有机器的虚拟 IP 地址(Virtual IP Address,VIP),配置成跟负载均衡器的虚拟 IP 一样,这样经均衡器转发后的数据包,就能在真实服务器中顺利地使用。
另外,也正是因为实际处理请求的真实物理服务器 IP 和数据请求中的目的 IP 是一致的,所以响应结果就不再需要通过负载均衡服务器进行地址交换,我们可以把响应结果的数据包直接从真实服务器返回给用户的客户端,避免负载均衡器网卡带宽成为瓶颈,所以数据链路层的负载均衡效率是相当高的。
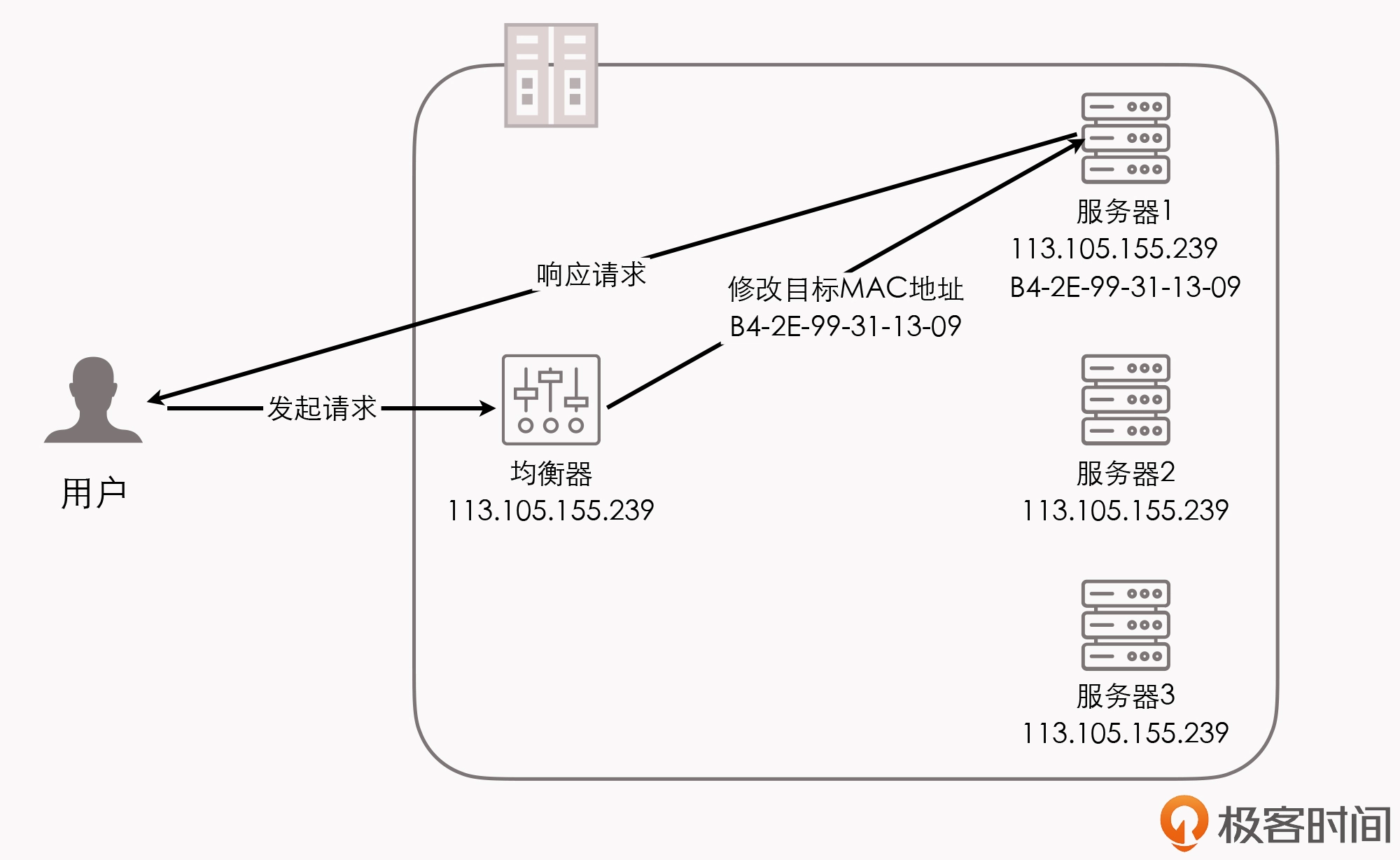
这种传输方式被称为三角传输,返回的流量不经过LB,避免负载均衡器网卡带宽成为瓶颈,效率较高.
数据链路层的劣势也很明显,因为其需要通过修改MAC地址的方式进行工作,因此真实目标服务器必须和LB服务器在同一子网下。
网络层LB
与数据链路层类似的,网络层是通过修改三层数据包的目标IP地址进行工作:
其修改方式主要有两种:
- 第一种是保持原来的数据包不变,新创建一个数据包,把原来数据包的 Headers 和 Payload 整体作为另一个新的数据包的 Payload,在这个新数据包的 Headers 中,写入真实服务器的 IP 作为目标地址,然后把它发送出去。
这种方式需要在接收时重新进行拆包,取出原来要发送的数据包,这样,IP数据包的源IP和目的IP无变化,真实服务器仍然可以直接将数据发送给客户端,不需要经过LB,也即仍具有三角传输的特性。
这种方式被称为IP隧道,因为其工作在网络层,可以跨VLAN进行传输,但要求目标服务器支持IP隧道协议。
- 第二种方式直接把数据包 Headers 中的目标地址改掉,修改后原本由用户发给均衡器的数据包,也会被三层交换机转发送到真实服务器的网卡上,而且因为没有经过 IP 隧道的额外包装,也就无需再拆包了。
但这样的话,真实服务器在将数据返回给客户端时,就会使用自己的IP作为源IP,客户端一看:“我想要的是A服务器响应,你给我来了个B服务器响应,滚犊子”,不能正常处理这个应答,因此必须让响应返回LB再发给客户端。
这种方式类似于NAT协议,也因此被称为NAT模式的负载均衡。由于所有的流量都需要LB进行转发,因此这种方式的效率相对较低。
还有一种更加彻底的方式Source NAT(SNAT),LB不仅将目标IP修改为真实服务器地址,而且将源IP也修改为自己的IP地址。这样做的好处在于对于真实服务器是彻底透明的,但会丢失客户端IP信息。
3.2 七层LB
数据链路层LB和网络层LB都是“转发”模式,即直接将承载着TCP报文的底层数据包转发到真实服务器上,此时客户端到响应请求的真实服务器维持着同一条 TCP 通道,即客户端通过一个TCP连接直接跟真实服务器对话。
但工作在四层后的LB不能以这种方式工作(四层以上看不到TCP数据包),必须通过“代理”的方式,此时,客户端与真实服务器之间没有直连的TCP连接,而是通过客户端-LB,LB-真实服务器两个连接来进行对话。
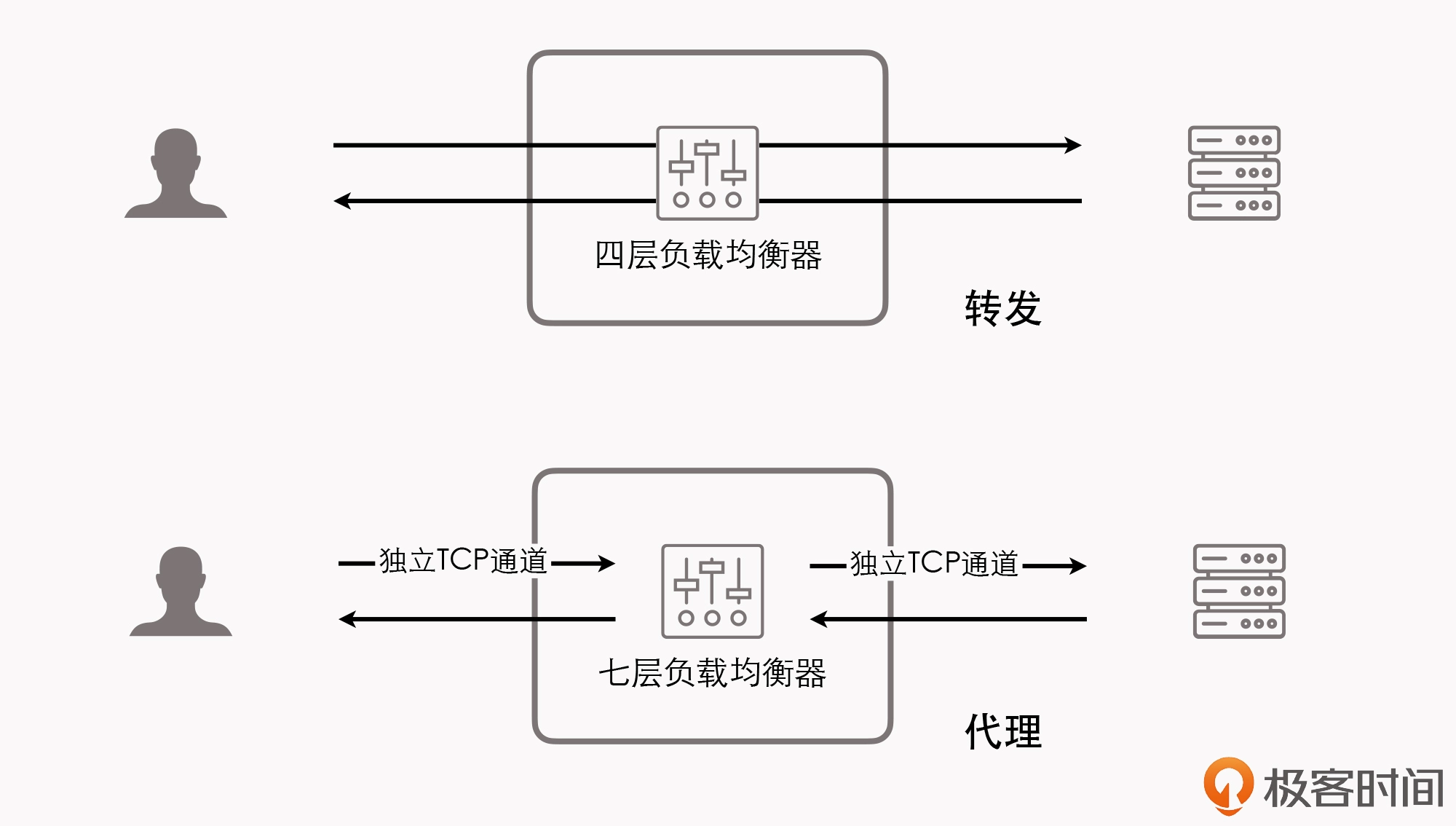
这样,七层负载均衡器肯定是无论如何比不过四层负载均衡器的。毕竟它比四层负载均衡器至少要多一轮 TCP 握手,还有着跟 NAT 转发模式一样的带宽问题,而且通常要耗费更多的 CPU,因为可用的解析规则远比四层丰富。
但七层LB可以感知应用层通讯的具体内容,这就意味着它能够做出更明智的决策,玩出更多的花样来:
- 七层LB可以用来做静态资源缓存、协议升级、安全防护、访问控制等
- 实现更智能化的路由
- 某些安全攻击可以由七层负载均衡器来抵御
- 进行微服务治理等
3.3 LB策略
负载均衡的两大职责是“选择谁来处理用户请求”,“如何将用户请求转发出去”,四层、七层LB解决的问题是如何将用户请求转发出去,而对于“选择谁来处理用户请求”,则需要具体的LB策略。
轮循均衡(Round Robin)即每一次来自网络的请求,会轮流分配给内部中的服务器,从 1 到 N 然后重新开始。这种均衡算法适用于服务器组中的所有服务器都有相同的软硬件配置,并且平均服务请求相对均衡的情况。
权重轮循均衡(Weighted Round Robin)即根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。比如,服务器 A 的权值被设计成 1,B 的权值是 3,C 的权值是 6,则服务器 A、B、C 将分别接收到 10%、30%、60%的服务请求。这种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
随机均衡(Random)即把来自客户端的请求随机分配给内部中的多个服务器。这种均衡算法在数据足够大的场景下,能达到相对均衡的分布。权重随机均衡(Weighted Random)这种均衡算法类似于权重轮循算法,不过在处理请求分担的时候,它是个随机选择的过程。
一致性哈希均衡(Consistency Hash)即根据请求中的某些数据(可以是 MAC、IP 地址,也可以是更上层协议中的某些参数信息)作为特征值,来计算需要落在哪些节点上,算法一般会保证同一个特征值,每次都一定落在相同的服务器上。这里一致性的意思就是,保证当服务集群的某个真实服务器出现故障的时候,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
响应速度均衡(Response Time)即负载均衡设备对内部各服务器发出一个探测请求(如 Ping),然后根据内部中各服务器对探测请求的最快响应时间,来决定哪一台服务器来响应客户端的服务请求。这种均衡算法能比较好地反映服务器的当前运行状态,但要注意,这里的最快响应时间,仅仅指的是负载均衡设备与服务器间的最快响应时间,而不是客户端与服务器间的最快响应时间。
最少连接数均衡(Least Connection)客户端的每一次请求服务,在服务器停留的时间可能会有比较大的差异。那么随着工作时间加长,如果采用简单的轮循或者随机均衡算法,每一台服务器上的连接进程可能会产生极大的不平衡,并没有达到真正的负载均衡。所以,最少连接数均衡算法就会对内部中需要负载的每一台服务器,都有一个数据记录,也就是记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,就把当前请求分配给连接数最少的服务器,使均衡更加符合
3.4 LB的软硬件实现
负载均衡器的实现有“软件均衡器”和“硬件均衡器”两类。
在软件均衡器方面,又分为直接建设在操作系统内核的均衡器和应用程序形式的均衡器两种。前者的代表是 LVS(Linux Virtual Server),后者的代表有 Nginx、HAProxy、KeepAlived,等等;前者的性能会更好,因为它不需要在内核空间和应用空间中来回复制数据包;而后者的优势是选择广泛,使用方便,功能不受限于内核版本。
在硬件均衡器方面,往往会直接采用应用专用集成电路(Application Specific Integrated Circuit,ASIC)来实现。因为它有专用处理芯片的支持,可以避免操作系统层面的损耗,从而能够达到最高的性能。这类的代表就是著名的 F5 和 A10 公司的负载均衡产品。
References
https://time.geekbang.org/column/article/327417
https://www.cloudflare.com/zh-cn/learning/performance/what-is-dns-load-balancing/