在使用top命令查看系统状态时,会出现一堆参数,这些参数分别代表什么意思呢?
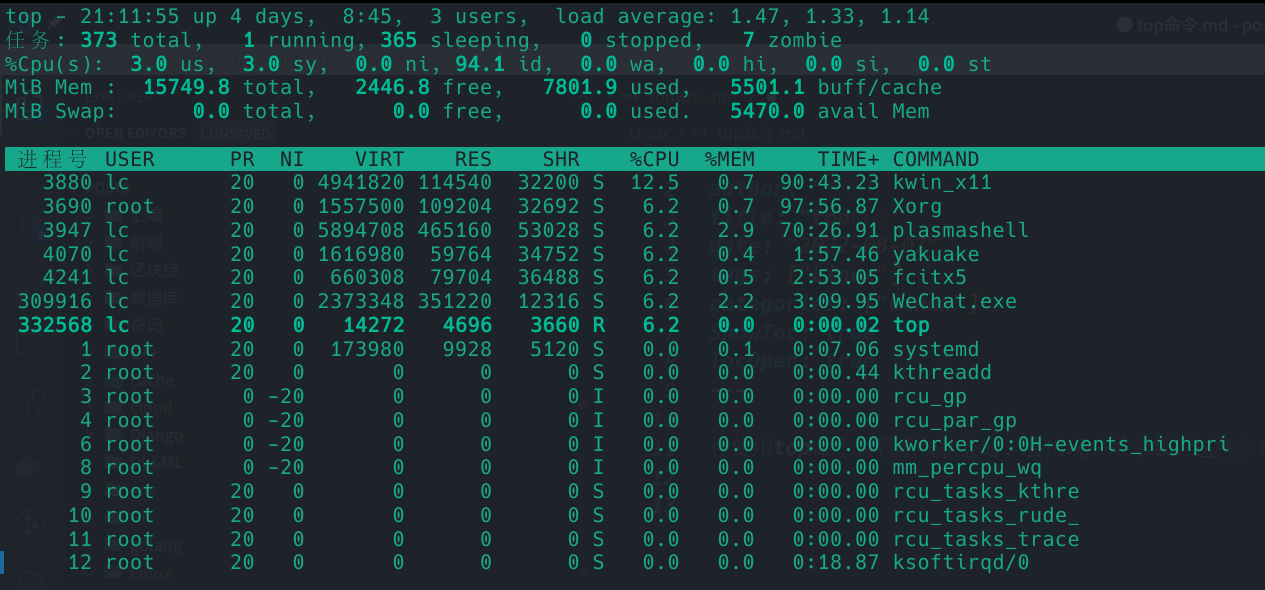
第一行

首先打印了当前时间21:11:55,然后是系统已经启动了多久up 4 days, 8:45,我已经4天8小时45分钟没关机了。。
然后当前有3个用户登录3 users,load average是1.47, 1.33, 1.14
load average
load average后面有三个值,分别代表过去 1 分钟,5 分钟,15 分钟在这个节点上的 load average.
Load Average 是一种 CPU 资源需求的度量。
举例来说,对于一个单个 CPU 的系统,如果在 1 分钟的时间里,处理器上始终有一个进程在运行,同时操作系统的进程可运行队列中始终都有 9 个进程在等待获取 CPU 资源。那么对于这 1 分钟的时间来说,系统的"load average"就是 1+9=10,这个定义对绝大部分的 Unix 系统都适用。
对于 Linux 来说,如果只考虑 CPU 的资源,Load Averag 等于单位时间内正在运行的进程加上可运行队列的进程,这个定义也是成立的。
对于load average的理解有以下三点:
不论计算机 CPU 是空闲还是满负载,Load Average 都是 Linux 进程调度器中可运行队列(Running Queue)里的一段时间的平均进程数目。
计算机上的 CPU 还有空闲的情况下,CPU Usage 可以直接反映到"load average"上,什么是 CPU 还有空闲呢?具体来说就是可运行队列中的进程数目小于 CPU 个数,这种情况下,单位时间进程 CPU Usage 相加的平均值应该就是"load average"的值。
计算机上的 CPU 满负载的情况下,计算机上的 CPU 已经是满负载了,同时还有更多的进程在排队需要 CPU 资源。这时"load average"就不能和 CPU Usage 等同了。
比如对于单个 CPU 的系统,CPU Usage 最大只是有 100%,也就 1 个 CPU;而"load average"的值可以远远大于 1,因为"load average"看的是操作系统中可运行队列中进程的个数。
要注意的是,平均负载统计了这两种情况的进程:
第一种是 Linux 进程调度器中可运行队列(Running Queue)一段时间(1 分钟,5 分钟,15 分钟)的进程平均数。
第二种是 Linux 进程调度器中休眠队列(Sleeping Queue)里的一段时间的 TASK_UNINTERRUPTIBLE 状态下的进程平均数。所以,最后的公式就是:Load Average= 可运行队列进程平均数 + 休眠队列中不可打断的进程平均数
因此,Load Average= 可运行队列进程平均数 + 休眠队列中不可打断的进程平均数
第二行

第二行主要记录了当前系统中的进程数量和其状态信息。
例如当前我的系统中有373个进程totol 373,但只有一个进程正在运行1 running,365个在sleep365 sleep,0个stoped0 stoped,7个为僵尸进程7 zombie
zombie 状态下
子进程结束时父进程没有调用wait()/waitpid()等待子进程结束,那么就会产生僵尸进程。
原因是子进程结束时并没有真正退出,而是留下一个僵尸进程的数据结构在系统进程表中,等待父进程清理,如果父进程已经退出则会由init进程接替父进程进行处理(收尸)。之所以要留下一个僵尸进程zombie是因为父进程可能会需要子进程的的某些结果。
由此可见,如果父进程不作为并且又不退出,就会有大量的僵尸进程,每个僵尸进程会占用进程表的一个位置(slot),如果僵尸进程太多会导致系统无法创建新的进程,因为进程表的容量是有限的。所以当zombie这个指标太大时需要引起我们的注意。
杀死僵尸进程的方法不是直接对其进行kill,而是去找他的父进程,对其附进程进行kill -9,毕竟,僵尸是杀不死的嘛。。
第三行

第三行比较复杂,值比较多,先来总体看看:
us: user 表示用户态的CPU时间比例sy: system 表示内核态的CPU时间比例wa: iowait 表示处于IO等待的CPU时间比例ni: nice 表示运行低优先级进程的CPU时间比例id: idle 表示空闲CPU时间比例hi: hard interrupt 表示处理硬中断的CPU时间比例si: soft interrupt 表示处理软中断的CPU时间比例st: steal 表示当前系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间比例。
解释一下:
对于下图,横向为时间轴,上半部分代表系统用户态,下半部分代表系统内核态,假设系统只有一个CPU
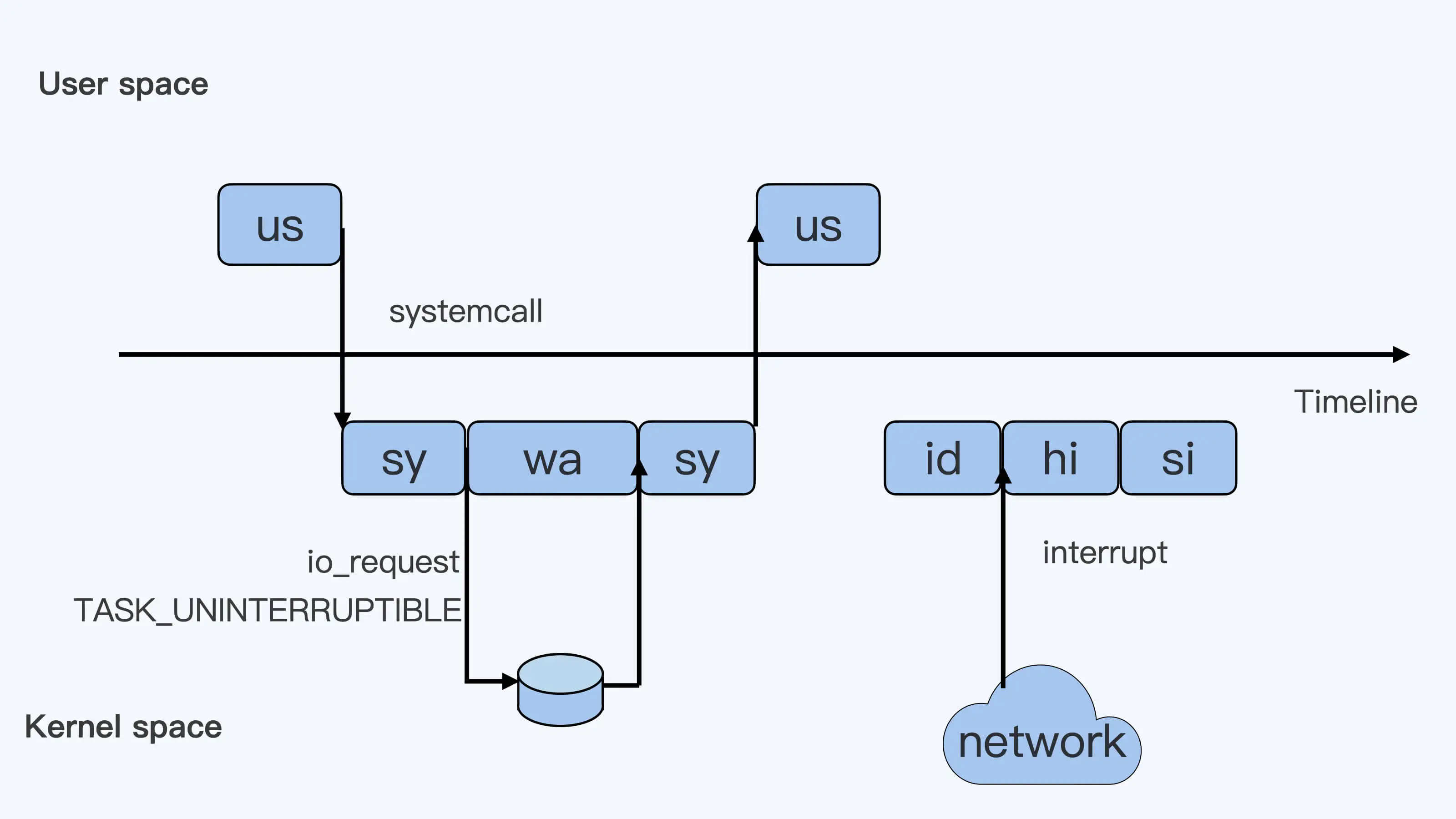
假设一个用户程序开始运行了,那么就对应着第一个"us"框,“us"是"user"的缩写,代表 Linux 的用户态 CPU Usage。普通用户程序代码中,只要不是调用系统调用(System Call),这些代码的指令消耗的 CPU 就都属于"us”。
当这个用户程序代码中调用了系统调用,比如说 read() 去读取一个文件,这时候这个用户进程就会从用户态切换到内核态。
内核态 read() 系统调用在读到真正 disk 上的文件前,就会进行一些文件系统层的操作。那么这些代码指令的消耗就属于"sy",这里就对应上面图里的第二个框。“sy"是 “system"的缩写,代表内核态 CPU 使用。
接下来,这个 read() 系统调用会向 Linux 的 Block Layer 发出一个 I/O Request,触发一个真正的磁盘读取操作。
这时候,这个进程一般会被置为 TASK_UNINTERRUPTIBLE。而 Linux 会把这段时间标示成"wa”,对应图中的第三个框。“wa"是"iowait"的缩写,代表等待 I/O 的时间,这里的 I/O 是指 Disk I/O。
紧接着,当磁盘返回数据时,进程在内核态拿到数据,这里仍旧是内核态的 CPU 使用中的"sy”,也就是图中的第四个框。
然后,进程再从内核态切换回用户态,在用户态得到文件数据,这里进程又回到用户态的 CPU 使用,“us”,对应图中第五个框。
好,这里我们假设一下,这个用户进程在读取数据之后,没事可做就休眠了。并且我们可以进一步假设,这时在这个 CPU 上也没有其他需要运行的进程了,那么系统就会进入"id"这个步骤,也就是第六个框。“id"是"idle"的缩写,代表系统处于空闲状态。
如果这时这台机器在网络收到一个网络数据包,网卡就会发出一个中断(interrupt)。相应地,CPU 会响应中断,然后进入中断服务程序。
这时,CPU 就会进入"hi”,也就是第七个框。“hi"是"hardware irq"的缩写,代表 CPU 处理硬中断的开销。由于我们的中断服务处理需要关闭中断,所以这个硬中断的时间不能太长。
但是,发生中断后的工作是必须要完成的,如果这些工作比较耗时那怎么办呢?Linux 中有一个软中断的概念(softirq),它可以完成这些耗时比较长的工作。
你可以这样理解这个软中断,从网卡收到数据包的大部分工作,都是通过软中断来处理的。那么,CPU 就会进入到第八个框,“si”。这里"si"是"softirq"的缩写,代表 CPU 处理软中断的开销。
这里你要注意,无论是"hi"还是"si”,它们的 CPU 时间都不会计入进程的 CPU 时间。这是因为本身它们在处理的时候就不属于任何一个进程。
除此之外,还有ni,是"nice"的缩写,这里表示如果进程的 nice 值是正值(1-19),代表优先级比较低的进程运行时所占用的 CPU。
还有st,st是"steal"的缩写,是在虚拟机里用的一个 CPU 使用类型,表示有多少时间是被同一个宿主机上的其他虚拟机抢走的。
第四、五行

第4、5行显示的是系统内存使用,单位KiB。totol 表示总内存,free 表示没使用过的内容,used是已经使用的内存。buff表示用于读写磁盘缓存的内存,cache表示用于读写文件缓存的内存,avail表示可用的应用内存。
Swap: total表示能用的swap总量, free表示剩余,used表示已经使用的,avail表示可用的交换区大小。
其他

从第6行开始,表示的是具体的进程状态:
PID进程IDUSER进程所有者的用户名,例如rootPR进程调度优先级NI进程nice值(优先级),越小的值代表越高的优先级VIRT进程使用的虚拟内存RES进程使用的物理内存(不包括共享内存)SHR进程使用的共享内存CPU进程使用的CPU占比MEM进程使用的内存占比TIME进程启动后到现在所用的全部CPU时间COMMAND进程的启动命令(默认只显示二进制,top -c能够显示命令行和启动参数)