翻译自:TCMalloc : Thread-Caching Malloc(性能测试部分没有翻译)
动机
在我测试过的所有malloc(动态内存分配器)中,TCMalloc比glibc 2.3 malloc(作为一个单独的库称作ptmalloc2)以及其他内存分配器都要快。对于小内存对象来说,在Intel® Pentium® 4 Processor 2.80 GHzCPU上ptmalloc2执行一次内存分配/回收操作需要大约300ns,而TCMalloc完成相同的操作只需要50ns。显然对于内存分配操作来说,速度十分重要,因为如果内存分配不够及时,开发人员就倾向于在malloc上编写他们自己的空闲列表,这会造成额外的复杂性以及更多的内存占用,除非开发人员非常小心的估算空闲列表的大小并清理其中的空闲对象。
TCMalloc也降低了多线程应用中的锁冲突。对于小内存对象来说几乎不存在冲突。对于大内存对象来说,TCMalloc尝试使用细粒度和高效的自旋锁。ptmalloc2也尝试通过一些方法降低锁冲突,其为每个线程分配一个arena空间,但ptmalloc2对于arena空间的使用存在一个大问题:在ptmalloc2中内存将不可能从一个arena空间转移到另一个arena空间,也即内存不可以在线程之间进行二次分配。这会导致巨大的内存浪费。例如,在一个Google应用中,阶段一为其数据结构分配了大约300MB。当其第一阶段结束后,阶段二将在相同的地址空间上开始。如果阶段二分配了一个与阶段一不同的arena空间,那么阶段二的计算将不会重复使用阶段一留下的任何内存空间,而是重新分配另一个300MB内存空间。这种内存的“blowup”问题同样出现在其他应用中。
TCMolloc的另一个优点是针对小内存对象的空间的有效利用。例如,可以将8N bytes大小的对象分配到8N*1.01bytes的空间上,即只需要1%的空间开销。ptmalloc2对每一个对象分配一个4bytes的头,(我认为)这种方式将本来只需要8N bytes大小对象变成了需要16N bytes
用法
要想使用TCMalloc,只要使用-l tcmalloc标志将tcmalloc链接到你的应用。
你也可以在不是你编译的应用中使用tcmalloc,通过使用LD_PRELOAD环境变量
LD_PRELOAD="/usr/lib/libtcmalloc.so"
但我们不推荐在非必要的情况下使用这种方式。
如果你只想要链接一个没有堆检查器和分析器的TCMalloc版本(可能想要减小二进制包的大小),你可以链接libtcmalloc_minimal
概览
TCMalloc为每个线程分配一个本地线程缓存thread-local cache。小的内存分配将直接被本地线程缓存满足。对象按需从中间部件central data structure移动到本地线程缓存。定期的垃圾收集被用来把内存从本地线程缓存放回中间部件central data structure。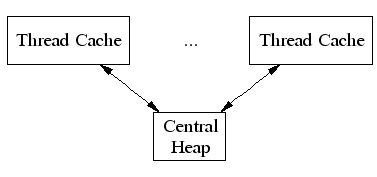
TCMalloc对于大小<=32K的(小)对象的处理方式与大对象不同。大对象由顶层堆管理器central heap使用页级的分配器直接分配。(一个页面是一个4K对齐的内存区域),同时,大对象总是页对齐并且占据整数个页面。
页面可被一系列的小对象瓜分为大小相同的区域。例如:一个4K的内存将被32个对象分割为每个128bytes的内存序列。
小对象的分配
每个小对象都对应于170个可分配内存大小size-classes中的一种,例如,大小范围在961-1024bytes的对象将占据1024bytes。这些内存大小级别被不同大小的间距分隔开,其中较小尺寸为8bytes,大尺寸为16bytes,更大的是32bytes,以此类推。最大的空间是256bytes(对于size-classes)大于等于2k。
本地线程缓存thread-local cache持有不同size-class的空闲链表。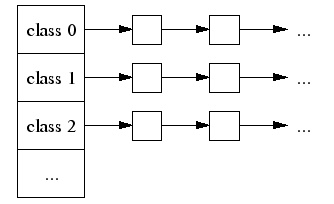
当分配一个小对象时:
- 将其大小映射到相应的
size-class - 为当前线程在其
thread-local cache的(内存)空闲链表中寻找对应size-class链表 - 如果空闲链表非空,那么我们将链表的第一个对象移出并返回之,当执行这种快速路径时,
TCMalloc不需要任何锁,因为加锁解锁这一对操作在2.8GHz的机器上大约需要100ns,这使得内存分配速度明显加快。
如果空闲链表为空:
- 从
central free list(central data structure)获取一系列对应大小的内存。(central data structure被所有线程共享) - 将获取到的内存放入
thread-local cache的空闲链表。 - 返回其中一个新获取的内存对象给应用
如果central free list也为空:
- 从
central page allocator(central heap)分配一系列页面 - 将这些页面分割为对应
size-class大小的内存对象 - 将这些新的内存对象放入
central free list - 像之前所说将内存对象放入
thread-local free list
大内存的分配
大对象被对齐到页大小(4K),并且被central page heap管理。central page heap同样是一个空闲列表数组。当数组下标i小于256时,第k个数组元素是一个每个节点包含k个页的空闲列表,而第256个数组元素中,链表的节点长度大于256页
一次分配k个页面的需求将被第k个空闲列表满足。如果这个空闲列表为空,那么将在下一个空闲列表中寻找,以此类推。如果有需要的话,我们将在最后一个空闲列表中获得内存对象。如果这仍然失败,那么我们直接从操作系统中获取内存。
如果一次要求k个页的请求被长度大于k的空闲链表满足,那么剩下的内存将被插入到central page heap合适的空闲链表中.
跨度(span)
TCMalloc管理的堆中有一系列的页。一系列连续的页由span对象表示。span可以被分配或释放。如果被释放,那么span是页堆链表中的一项。如果被分配,那么他是被应用所持有的一个大内存对象,或是已被分割为一个个小内存对象。如果其被分割为小内存对象,那么它的size-class将被记录下来。
可以用以页号作为下标的central array来表明页属于哪个span。例如,在下图中,spana 占据了两个页,sapnb占据了1个页, sapnc占据了5个页,sapnd占据了3个页。
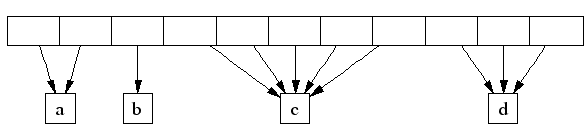
一个32位地址空间可被分为2的20次方个4K大小的页,所以一个central array持有4MB空闲看起来是合理的。在64位机器上,我们使用3级基数树而不是数组来将页号映射到相应的span指针。
解除分配
当一个对象被解除分配,我们计算它的页号并且在central array寻找其对应的span对象。这个span对象告诉我们这个对象是否是小对象以及它的size-class(如果是小对象的话)。如果对象是小对象,我们将其插入到当前线程的thread-local cache中的空闲链表中。如果当前thread-local cache超出了预设的大小(一般为2MB),那么我们进行一个垃圾回收以将其从thread-local cache移到central free list。
如果这个对象是大对象,那么sapn告诉我们这个对象包含的页号。假设其包含的页号为[p, q]。我们同样会查看相邻的[p-1][q+1]号页,如果这些相邻的页为空闲状态,那么我们将这些空闲页与[p, q]页合并。最后得到的span将被插入到page heap中合适的空闲列表中。
面向小对象的central free list
正如之前所说,我们为每个size-class维护了一个central free list。每个central free list被组织为两层数据结构:一系列span对象,以及span中的空闲对象列表。
被分配的对象来自某些span的空闲链表的头部。(如果所有的span都持有空的空闲链表,那么将从central page heap分配合适大小的span)
在对象被返回时,其将被添加到span持有的链表中。如果链表的长度等于span中的小对象数目,那么说明这个span现在已经被完全释放,其应该被返还到page heap.
thread-local cache的垃圾收集
当thread-local cache的总大小超过2MB时,就会触发对其的垃圾收集。当线程增加数时,这个垃圾收集门槛将自动减少,这样我们就不会在具有大量线程的程序中浪费过多的内存。
我们将遍历所有cache中的空闲列表并且将一些对象从空闲列表中移动到相应的central list。
被移动对象的数目是使用每个列表上低位标记L确定的,L记录自上次垃圾回收以来列表的最小长度。注意,我们可以在最后一次垃圾回收时将列表缩短L个对象而无需对central list进行任何额外访问。我们将这部分历史记录作为对未来访问的一个预测,将L/2个对象从thread-local cache移动到对应的central free list。这个算法有一个很好的特性,如果一个线程停止使用特定大小的内存,那么所有该大小的对象将被快速的从thread-local cache移动到central free list,从而这些对象可以被其他线程使用。