1. wazsmwazsm/mortar(★74)
简单介绍
创建一个容量为 N 的池, 在池容量未满时, 每塞入一个任务(生产任务), 任务池开启一个 worker (建立协程) 去处理任务(消费任务)。 当任务池容量赛满,每塞入一个任务(生产任务), 任务会被已有的 N 个 worker 抢占执行(消费任务),达到协程限制的功能。但worker创建后不会回收,除非将整个pool撤销。
结构
type Task struct {
Handler func(v ...interface{}) // 函数签名
Params []interface{} // 参数
}
// Pool task pool
type Pool struct {
capacity uint64 // 池的容量,自行制定
runningWorkers uint64 // 正在运行的worker
status int64 // 池的状态
chTask chan *Task // 任务队列,worker从中获取任务
PanicHandler func(interface{}) // 自定义的PanicHandler,防止因某个goroutine发生panic而导致服务崩溃。
sync.Mutex // 全局锁
}
核心代码
// Put put a task to pool
func (p *Pool) Put(task *Task) error {
p.Lock() // 加锁,防止数据竞争
defer p.Unlock()
if p.status == STOPED { // 检查池是否还在运行
return ErrPoolAlreadyClosed
}
// run worker
if p.GetRunningWorkers() < p.GetCap() { // worker数量尚未达到容量限制,新建一个worker
p.run() // 这里存在一个问题,若池中有空闲的worker,也会创建一个新的worker,这个worker创建后也会空闲,存在资源浪费
}
// send task
if p.status == RUNNING {
p.chTask <- task // 向任务队列发送任务
}
return nil
}
func (p *Pool) run() {
p.incRunning() // worker计数+1
go func() {
defer func() { // 防止因某个goroutine发生panic而导致服务崩溃
p.decRunning() // worker计数减1
if r := recover(); r != nil {
if p.PanicHandler != nil {
p.PanicHandler(r) // 自定义了panic后操作
} else {
log.Printf("Worker panic: %s\n", r) // panic后默认操作
}
}
p.checkWorker() // 检查是否还有worker在运行,保持最少一个worker
}()
for { // worker 保持运行
select {
case task, ok := <-p.chTask: // 接收task
if !ok { // 当任务队列被关闭是goroutine退出
return
}
task.Handler(task.Params...) // 执行任务
}
}
}()
}
在Put函数中,每当放入一个新任务之前,都会直接创建一个新的worker,这显然不甚合理,因为此时池中可能存在空闲的worker,应设法利用这些空闲的worker而不是创建新的worker。
尝试优化
一种优化思路是:在Pool对象中增加chIdle chan struct{}字段,作为空闲标志。放入任务之前首先检查chIdle是否存在空闲标志,若存在,则说明此时存在空闲worker,不需创建新的worker,只需将task放入即可。
而若chIdle中不存在空闲标志,则检查worker数量是否达到限制,然后创建新的worker。
优化后的核心代码如下:
type Pool struct {
capacity uint64
runningWorkers uint64
status int64
chTask chan *Task
chIdle chan struct{}
PanicHandler func(interface{})
sync.Mutex
}
func (p *Pool) Put(task *Task) error {
p.Lock()
defer p.Unlock()
if p.status == STOPED {
return ErrPoolAlreadyClosed
}
select {
case <-p.chIdle:
default:
if p.GetRunningWorkers() < p.GetCap() {
p.run()
}
}
// send task
if p.status == RUNNING {
p.chTask <- task
}
return nil
}
func (p *Pool) run() {
p.incRunning()
p.chIdle <- struct{}{}
go func() {
defer func() {
p.decRunning()
if r := recover(); r != nil {
if p.PanicHandler != nil {
p.PanicHandler(r)
} else {
log.Printf("Worker panic: %s\n", r)
}
}
p.checkWorker() // check worker avoid no worker running
}()
for {
select {
case task, ok := <-p.chTask:
if !ok {
return
}
task.Handler(task.Params...)
p.chIdle <- struct{}{}
}
}
}()
}
优化前后banchmark测试数据对比如下:
优化前:BenchmarkPut-4 815876 1460 ns/op 0 B/op 0 allocs/op
优化后:BenchmarkPut-4 948046 1323 ns/op 0 B/op 0 allocs/op
优化前: BenchmarkPutTimelife-4 1000000 1287 ns/op 0 B/op 0 allocs/op
优化后: BenchmarkPutTimelife-4 930015 1356 ns/op 0 B/op 0 allocs/op
优化前: BenchmarkPoolPutSetTimes-4 1 1433118500 ns/op 12104 B/op 52 allocs/op
优化后: BenchmarkPoolPutSetTimes-4 1 1474117300 ns/op 8504 B/op 42 allocs/op
优化前: BenchmarkPoolTimeLifeSetTimes-4 1 1277515600 ns/op 10208 B/op 47 allocs/op
优化后: BenchmarkPoolTimeLifeSetTimes-4 1 1279696300 ns/op 7928 B/op 39 allocs/op
基本使用
package main
import (
"fmt"
"sync"
"github.com/wazsmwazsm/mortar"
)
func main() {
// 创建容量为 10 的任务池
pool, err := mortar.NewPool(10)
if err != nil {
panic(err)
}
wg := new(sync.WaitGroup)
for i := 0; i < 1000; i++ {
wg.Add(1)
// 创建任务
task := &mortar.Task{
Handler: func(v ...interface{}) {
wg.Done()
fmt.Println(v)
},
}
// 添加任务函数的参数
task.Params = []interface{}{i, i * 2, "hello"}
// 将任务放入任务池
pool.Put(task)
}
wg.Add(1)
// 再创建一个任务
pool.Put(&mortar.Task{
Handler: func(v ...interface{}) {
wg.Done()
fmt.Println(v)
},
Params: []interface{}{"hi!"}, // 也可以在创建任务时设置参数
})
wg.Wait()
// 安全关闭任务池(保证已加入池中的任务被消费完)
pool.Close()
// 如果任务池已经关闭, Put() 方法会返回 ErrPoolAlreadyClosed 错误
err = pool.Put(&mortar.Task{
Handler: func(v ...interface{}) {},
})
if err != nil {
fmt.Println(err) // print: pool already closed
}
}
总结 goroutine的复用很好的减小了大批量异步任务中的内存分配与垃圾回收压力,但不能回收的goroutine可能在任务波峰过去后成为内存浪费(不撤销池的情况下),适合用于长期大规模执行并发任务的情况下。
2. go-playground/pool(★614)
简单介绍
提供了LimitedPool,UnLimitedPool两种池,分别可以创建(worker数量)有限的worker和无限的worker;提供了Unit task和batch Task两种任务模式,分别适用于单次偶发任务及多次重复任务。LimitedPool,UnLimitedPool都实现了Pool接口。可长期保持运行。
系统结构
type Pool interface {
Queue(fn WorkFunc) WorkUnit // 传入要执行的任务,立即开始执行
Reset() // 重新初始化一个池
Cancel() // 取消所有未在运行的任务
Close() // 清除所有池数据并取消所有未提交的任务
Batch() Batch // 创建批量任务
}
核心代码
// passing work and cancel channels to newWorker() to avoid any potential race condition
// betweeen p.work read & write
func (p *limitedPool) newWorker(work chan *workUnit, cancel chan struct{}) {
go func(p *limitedPool) {
var wu *workUnit
defer func(p *limitedPool) {
if err := recover(); err != nil {
// ...
}
}(p)
var value interface{}
var err error
for {
select {
case wu = <-work:
// possible for one more nilled out value to make it
// through when channel closed, don't quite understand the why
if wu == nil {
continue
}
// support for individual WorkUnit cancellation
// and batch job cancellation
if wu.cancelled.Load() == nil {
value, err = wu.fn(wu)
wu.writing.Store(struct{}{})
// need to check again in case the WorkFunc cancelled this unit of work
// otherwise we'll have a race condition
if wu.cancelled.Load() == nil && wu.cancelling.Load() == nil {
wu.value, wu.err = value, err
// who knows where the Done channel is being listened to on the other end
// don't want this to block just because caller is waiting on another unit
// of work to be done first so we use close
close(wu.done)
}
}
case <-cancel:
return
}
}
}(p)
}
// Queue queues the work to be run, and starts processing immediately
func (p *limitedPool) Queue(fn WorkFunc) WorkUnit {
w := &workUnit{
done: make(chan struct{}),
fn: fn,
}
go func() {
p.m.RLock()
if p.closed {
w.err = &ErrPoolClosed{s: errClosed}
if w.cancelled.Load() == nil {
close(w.done)
}
p.m.RUnlock()
return
}
p.work <- w
p.m.RUnlock()
}()
return w
}
基本使用
Per Unit Work
package main
import (
"fmt"
"time"
"gopkg.in/go-playground/pool.v3"
)
func main() {
p := pool.NewLimited(10)
defer p.Close()
user := p.Queue(getUser(13))
other := p.Queue(getOtherInfo(13))
user.Wait()
if err := user.Error(); err != nil {
// handle error
}
// do stuff with user
username := user.Value().(string)
fmt.Println(username)
other.Wait()
if err := other.Error(); err != nil {
// handle error
}
// do stuff with other
otherInfo := other.Value().(string)
fmt.Println(otherInfo)
}
func getUser(id int) pool.WorkFunc {
return func(wu pool.WorkUnit) (interface{}, error) {
// simulate waiting for something, like TCP connection to be established
// or connection from pool grabbed
time.Sleep(time.Second * 1)
if wu.IsCancelled() {
// return values not used
return nil, nil
}
// ready for processing...
return "Joeybloggs", nil
}
}
func getOtherInfo(id int) pool.WorkFunc {
return func(wu pool.WorkUnit) (interface{}, error) {
// simulate waiting for something, like TCP connection to be established
// or connection from pool grabbed
time.Sleep(time.Second * 1)
if wu.IsCancelled() {
// return values not used
return nil, nil
}
// ready for processing...
return "Other Info", nil
}
}
Batch Work
package main
import (
"fmt"
"time"
"gopkg.in/go-playground/pool.v3"
)
func main() {
p := pool.NewLimited(10)
defer p.Close()
batch := p.Batch()
// for max speed Queue in another goroutine
// but it is not required, just can't start reading results
// until all items are Queued.
go func() {
for i := 0; i < 10; i++ {
batch.Queue(sendEmail("email content"))
}
// DO NOT FORGET THIS OR GOROUTINES WILL DEADLOCK
// if calling Cancel() it calles QueueComplete() internally
batch.QueueComplete()
}()
for email := range batch.Results() {
if err := email.Error(); err != nil {
// handle error
// maybe call batch.Cancel()
}
// use return value
fmt.Println(email.Value().(bool))
}
}
func sendEmail(email string) pool.WorkFunc {
return func(wu pool.WorkUnit) (interface{}, error) {
// simulate waiting for something, like TCP connection to be established
// or connection from pool grabbed
time.Sleep(time.Second * 1)
if wu.IsCancelled() {
// return values not used
return nil, nil
}
// ready for processing...
return true, nil // everything ok, send nil, error if not
}
}
总结 功能齐全,但好像用起来不太舒服。
3. ivpusic/grpool(★634)
简单介绍 用户可以提交task。 Dispatcher接受task,并将其发送给第一个可用的worker。 当worker完成处理工作时,将返回到workers pool。 worker数量和task队列大小是可配置的。
整个程序以一个调度器为核心,Pool通过调度器来调度worker,worker可复用,但任务结束时worker不会自动回收,不适合长期运行。只能传递无参任务。
系统结构
// Gorouting instance which can accept client jobs
type worker struct {
workerPool chan *worker // 工人池
jobChannel chan Job // 这个worker独有的任务队列
stop chan struct{}
}
type dispatcher struct {
workerPool chan *worker // 与worker是同一个workerPool
jobQueue chan Job // 与池共有的任务队列
stop chan struct{}
}
// Represents user request, function which should be executed in some worker.
type Job func()
type Pool struct {
JobQueue chan Job // 与dispatcher共有的任务队列
dispatcher *dispatcher
wg sync.WaitGroup
}
核心代码
func (w *worker) start() {
go func() { // 创建了一个worker
var job Job
for {
// worker free, add it to pool
w.workerPool <- w // 把worker放入worker池
select {
case job = <-w.jobChannel:
job()
case <-w.stop:
w.stop <- struct{}{}
return
}
}
}()
}
func (d *dispatcher) dispatch() {
for {
select {
case job := <-d.jobQueue:
worker := <-d.workerPool
worker.jobChannel <- job
case <-d.stop: // 停止所有worker
for i := 0; i < cap(d.workerPool); i++ {
worker := <-d.workerPool
worker.stop <- struct{}{}
<-worker.stop
}
d.stop <- struct{}{}
return
}
}
}
其程序运行图大致如下:
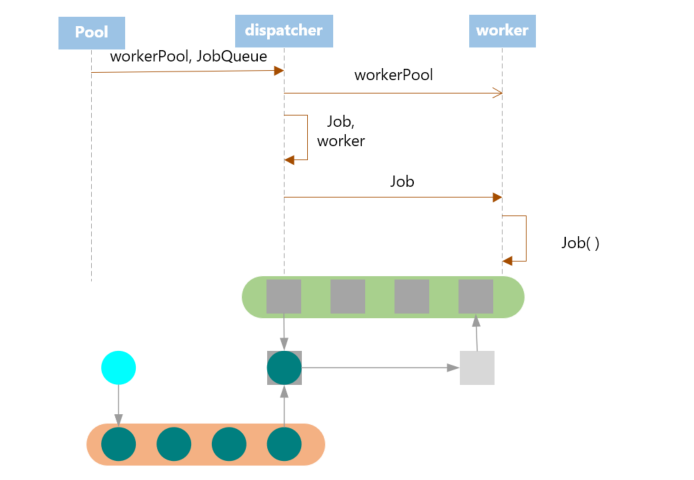 程序中存在一个
程序中存在一个workerPool,所有的worker都存在在这个池中,在程序的开始,会创建指定数目的worker,一次性放入池中(此后不再增加或减少)。每个worker有一个独有的jobChannel,这个jobChannel向worker传递其要执行的任务。
用户通过直接使用Pool的JobQueue来提交任务,提交的任务会由dispatcher接收,然后分配给某个空闲的worker,即放入其jobChannel中。
基本使用
package main
import (
"fmt"
"runtime"
"time"
"github.com/ivpusic/grpool"
)
func main() {
// number of workers, and size of job queue
pool := grpool.NewPool(100, 50)
// release resources used by pool
defer pool.Release()
// submit one or more jobs to pool
for i := 0; i < 10; i++ {
count := i
pool.JobQueue <- func() {
fmt.Printf("I am worker! Number %d\n", count)
}
}
// dummy wait until jobs are finished
time.Sleep(1 * time.Second)
}
性能测试
总结 设计简单,代码简洁清晰,但无panic恢复,不能动态扩容,任务传递简陋,感觉像是一个未完成版本的任务池
4. Jeffail/tunny(★2.4k)
![]()
简单介绍 有两种模式,第一种模式在池创建时即指定任务,池创建完成后任务不可更改,但可传入不同的参数,有返回值。第二种模式在创建时不给定任务,可在池创建后自行指配任务,但只可执行无参数任务且无返回值。支持超时机制,如果任务超过时间期限还没完成,则会终止并返回错误。
系统结构
type Pool struct {
queuedJobs int64 // 当前挂起的任务数
ctor func() Worker // 初始任务
workers []*workerWrapper
reqChan chan workRequest
workerMut sync.Mutex
}
type workerWrapper struct { // 负责管理worker和goroutine的生命周期
worker Worker
interruptChan chan struct{} // 中止信号通道
reqChan chan<- workRequest // 用于发送任务请求信号
closeChan chan struct{} // 退出信号通道
closedChan chan struct{} // 退出标志通道
}
type workRequest struct { // 任务请求信号
jobChan chan<- interface{} // 用于接收任务
retChan <-chan interface{} // 用于返回结果
interruptFunc func()
}
核心代码
func (p *Pool) Process(payload interface{}) interface{} {
// 省略了部分错误处理代码
request, open := <-p.reqChan
request.jobChan <- payload
payload, open = <-request.retChan // 同步等待任务完成
return payload
}
func (w *workerWrapper) run() {
jobChan, retChan := make(chan interface{}), make(chan interface{})
defer func() {
w.worker.Terminate()
close(retChan)
close(w.closedChan)
}()
for {
// NOTE: Blocking here will prevent the worker from closing down.
w.worker.BlockUntilReady()
select {
case w.reqChan <- workRequest{ // tunny.go:156
jobChan: jobChan,
retChan: retChan,
interruptFunc: w.interrupt,
}:
select {
case payload := <-jobChan: // tunny.go: 161
result := w.worker.Process(payload)
select {
case retChan <- result: // tunny.go: 163
case <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case _, _ = <-w.interruptChan:
w.interruptChan = make(chan struct{})
}
case <-w.closeChan:
return
}
}
}
根据以上代码,其主要执行过程如下:
- 某个goroutine空闲后,通过其
reqChan通道发送workRequest。workRequest中包括一个jobChan,用于生产者发送任务;一个retChan,用于返回执行结果;一个interrupt Func,用于任务执行超时时强行停止worker。需要注意的是,reqChan是池和workerWrapper共有的,因此发送的workRequest可直接被池接收到。 - 每当池中有新任务时,池尝试从
reqChan中获取一个workRequest,若获取到,则将任务通过workRequest持有的jobChan(即某个worker持有的jobChan)发送到worker - 发送完毕后,同步的从
retChan中读取结果。 - 若设置了超时时间,则在时间超时后会强制停止

基本使用
package main
import (
"io/ioutil"
"net/http"
"runtime"
"github.com/Jeffail/tunny"
)
func main() {
numCPUs := runtime.NumCPU()
pool := tunny.NewFunc(numCPUs, func(payload interface{}) interface{} {
var result []byte
// TODO: Something CPU heavy with payload
return result
})
defer pool.Close()
http.HandleFunc("/work", func(w http.ResponseWriter, r *http.Request) {
input, err := ioutil.ReadAll(r.Body)
if err != nil {
http.Error(w, "Internal error", http.StatusInternalServerError)
}
defer r.Body.Close()
// Funnel this work into our pool. This call is synchronous and will
// block until the job is completed.
result := pool.Process(input)
w.Write(result.([]byte))
})
http.ListenAndServe(":8080", nil)
}
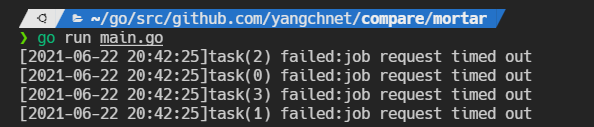
超时演示:
func main() {
p := tunny.NewFunc(4, func(payload interface{}) interface{} {
n := payload.(int)
result := fib(n)
time.Sleep(5 * time.Second)
return result
})
defer p.Close()
var wg sync.WaitGroup
wg.Add(4)
for i := 0; i < 4; i++ {
go func(i int) {
n := rand.Intn(30)
result, err := p.ProcessTimed(n, time.Second)
nowStr := time.Now().Format("2006-01-02 15:04:05")
if err != nil {
fmt.Printf("[%s]task(%d) failed:%v\n", nowStr, i, err)
} else {
fmt.Printf("[%s]fib(%d) = %d\n", nowStr, n, result)
}
wg.Done()
}(i)
}
wg.Wait()
}
func fib(n int) int {
if n <= 1 {
return 1
}
return fib(n-1) + fib(n-2)
}
5. panjf2000/ants(★5.8k)
![]()
简单介绍 启动服务之时先初始化一个 Goroutine Pool 池,这个 Pool 维护了一个类似栈的 LIFO 队列 ,里面存放负责处理任务的 Worker,然后在 client 端提交 task 到 Pool 中之后,在 Pool 内部,接收 task 之后的核心操作是:
- 检查当前 Worker 队列中是否有可用的 Worker,如果有,取出执行当前的 task;
- 没有可用的 Worker,判断当前在运行的 Worker 是否已超过该 Pool 的容量:{是 —> 再判断工作池是否为非阻塞模式:[是 ——> 直接返回 nil,否 ——> 阻塞等待直至有 Worker 被放回 Pool],否 —> 新开一个 Worker(goroutine)处理};
- 每个 Worker 执行完任务之后,放回 Pool 的队列中等待。
大致流程如下: 
这个库的亮点之一是其为每一个worker设置了过期时间,若worker空闲了一定时间就会被回收,很好的节约了资源。
系统结构
type Pool struct {
capacity int32 // 池的容量
running int32 // 正在运行的worker
workers workerArray // 存储可获取的worker
state int32 // 池的状态
lock sync.Locker
cond *sync.Cond // 条件变量,用于在条件满足时唤醒阻塞的程序
workerCache sync.Pool
blockingNum int // 被阻塞的数量
options *Options
}
type workerArray interface {
len() int
isEmpty() bool
insert(worker *goWorker) error
detach() *goWorker
retrieveExpiry(duration time.Duration) []*goWorker
reset()
}
type goWorker struct {
pool *Pool
task chan func()
recycleTime time.Time // recycleTime will be update when putting a worker back into queue
}
核心代码
func NewPool(size int, options ...Option) (*Pool, error) {
if expiry := opts.ExpiryDuration; expiry < 0 {
return nil, ErrInvalidPoolExpiry
} else if expiry == 0 {
opts.ExpiryDuration = DefaultCleanIntervalTime
}
p := &Pool{
capacity: int32(size),
lock: internal.NewSpinLock(),
options: opts,
}
p.workerCache.New = func() interface{} {
return &goWorker{
pool: p,
task: make(chan func(), workerChanCap),
}
}
if p.options.PreAlloc {
if size == -1 {
return nil, ErrInvalidPreAllocSize
}
p.workers = newWorkerArray(loopQueueType, size)
} else {
p.workers = newWorkerArray(stackType, 0)
}
p.cond = sync.NewCond(p.lock)
// Start a goroutine to clean up expired workers periodically.
go p.purgePeriodically() // 用一个独立的goroutine来回收过期的worker
return p, nil
}
func (w *goWorker) run() {
w.pool.incRunning()
go func() {
defer func() {
w.pool.decRunning()
w.pool.workerCache.Put(w)
if p := recover(); p != nil {
// ...
}
// Call Signal() here in case there are goroutine waiting for available workers.
w.pool.cond.Signal() // 发出信号唤醒某些阻塞等待worker的线程
}()
for f := range w.task {
if f == nil {
return
}
f()
if ok := w.pool.revertWorker(w); !ok { // 将worker重新放入池中循环利用
return
}
}
}()
}
// 返回一个可用的worker
func (p *Pool) retrieveWorker() (w *goWorker) {
spawnWorker := func() { // 返回一个可用的worker
w = p.workerCache.Get().(*goWorker)
w.run()
}
p.lock.Lock()
w = p.workers.detach() // 尝试从worker队列中取worker
if w != nil { // 从队列中获得了worker,直接返回
p.lock.Unlock()
} else if capacity := p.Cap(); capacity == -1 || capacity > p.Running() {
// 队列为空其worker数量未达到限制,则生成新的worker
p.lock.Unlock()
spawnWorker()
} else { // 队列为空且数量达到限制,则阻塞等待其他worker空闲
if p.options.Nonblocking {
p.lock.Unlock()
return
}
retry:
if p.options.MaxBlockingTasks != 0 && p.blockingNum >= p.options.MaxBlockingTasks {
p.lock.Unlock()
return
}
p.blockingNum++
p.cond.Wait() // 阻塞等待可用的worker
p.blockingNum--
var nw int
if nw = p.Running(); nw == 0 { // awakened by the scavenger
p.lock.Unlock()
if !p.IsClosed() {
spawnWorker()
}
return
}
if w = p.workers.detach(); w == nil {
if nw < capacity {
p.lock.Unlock()
spawnWorker()
return
}
goto retry
}
p.lock.Unlock()
}
return
}
// 定时清理过期worker
// purgePeriodically clears expired workers periodically which runs in an individual goroutine, as a scavenger.
func (p *Pool) purgePeriodically() {
heartbeat := time.NewTicker(p.options.ExpiryDuration)
defer heartbeat.Stop()
for range heartbeat.C {
if p.IsClosed() {
break
}
p.lock.Lock()
expiredWorkers := p.workers.retrieveExpiry(p.options.ExpiryDuration)
p.lock.Unlock()
// Notify obsolete workers to stop.
// This notification must be outside the p.lock, since w.task
// may be blocking and may consume a lot of time if many workers
// are located on non-local CPUs.
for i := range expiredWorkers {
expiredWorkers[i].task <- nil
expiredWorkers[i] = nil
}
// There might be a situation that all workers have been cleaned up(no any worker is running)
// while some invokers still get stuck in "p.cond.Wait()",
// then it ought to wake all those invokers.
if p.Running() == 0 {
p.cond.Broadcast()
}
}
}
func (wq *workerStack) retrieveExpiry(duration time.Duration) []*goWorker {
n := wq.len()
if n == 0 {
return nil
}
expiryTime := time.Now().Add(-duration)
index := wq.binarySearch(0, n-1, expiryTime)
wq.expiry = wq.expiry[:0]
if index != -1 {
wq.expiry = append(wq.expiry, wq.items[:index+1]...)
m := copy(wq.items, wq.items[index+1:])
for i := m; i < n; i++ {
wq.items[i] = nil
}
wq.items = wq.items[:m]
}
return wq.expiry
}
基本使用
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
"github.com/panjf2000/ants/v2"
)
var sum int32
func myFunc(i interface{}) {
n := i.(int32)
atomic.AddInt32(&sum, n)
fmt.Printf("run with %d\n", n)
}
func demoFunc() {
time.Sleep(10 * time.Millisecond)
fmt.Println("Hello World!")
}
func main() {
defer ants.Release()
runTimes := 1000
// Use the common pool.
var wg sync.WaitGroup
syncCalculateSum := func() {
demoFunc()
wg.Done()
}
for i := 0; i < runTimes; i++ {
wg.Add(1)
_ = ants.Submit(syncCalculateSum)
}
wg.Wait()
fmt.Printf("running goroutines: %d\n", ants.Running())
fmt.Printf("finish all tasks.\n")
// Use the pool with a function,
// set 10 to the capacity of goroutine pool and 1 second for expired duration.
p, _ := ants.NewPoolWithFunc(10, func(i interface{}) {
myFunc(i)
wg.Done()
})
defer p.Release()
// Submit tasks one by one.
for i := 0; i < runTimes; i++ {
wg.Add(1)
_ = p.Invoke(int32(i))
}
wg.Wait()
fmt.Printf("running goroutines: %d\n", p.Running())
fmt.Printf("finish all tasks, result is %d\n", sum)
}