极客时间《MySQL实战45讲》笔记
索引是什么,为何存在,以什么样的结构组织或存储索引?
简单来说,索引是一个目录,用来对数据进行快速的查找。就像一本厚厚的字典,想要查询某个字或者词语,我们固然可以一页页翻阅整本词典,但更好的方式是通过拼音索引或者笔画索引到这条记录。
索引可以有效减小查询的资源消耗,但索引不是毫无代价的,大量的创建索引会造成存储空间的损耗,我们要根据业务需求,有目的的创建对业务有帮助的索引。
在MySQL的InnoDB引擎中,索引是以B+树的形式存在的。B+树的节点存储在物理页上。
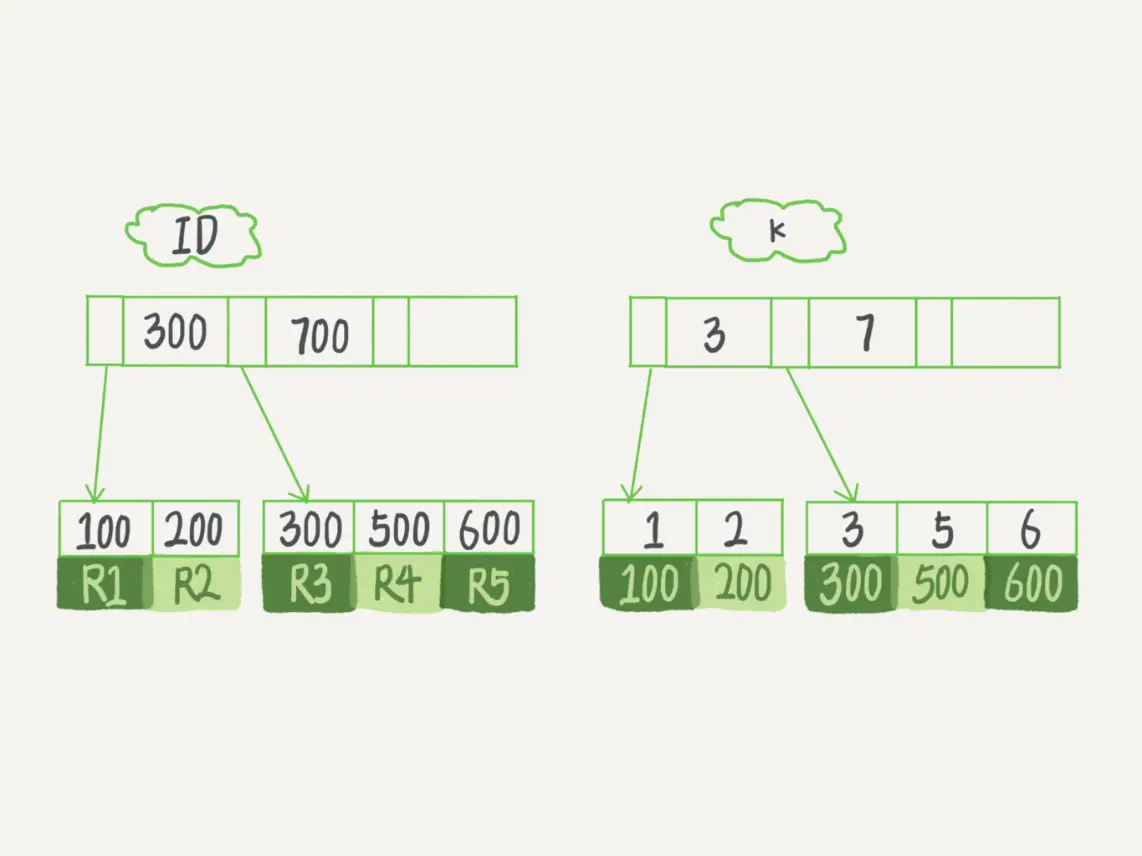
根据叶子节点的内容,索引类型分为主键索引和非主键索引。
主键索引的叶子节点存的是整行数据。在 InnoDB 里,主键索引也被称为聚簇索引(clustered index)。
非主键索引的叶子节点内容是主键的值。在 InnoDB 里,非主键索引也被称为二级索引(secondary index)。
为什么更推荐使用自增主键?
自增主键是指自增列上定义的主键,在建表语句中一般是这么定义的:
NOT NULL PRIMARY KEY AUTO_INCREMENT。
B+树天然就是有序的,当我们想在上图中插入一个ID=400的记录,那么可能需要进行页分裂操作,这就需要挪动后面的数据。但如果想插入一个ID=700的值,只需要在最后附加一条记录就可以,不需要对前面的值就行操作。
自增主键的插入数据模式,正符合了我们前面提到的递增插入的场景。每次插入一条新记录,都是追加操作,都不涉及到挪动其他记录,也不会触发叶子节点的分裂。
除了性能外,页分裂操作还影响数据页的利用率。原本放在一个页的数据,现在分到两个页中,整体空间利用率降低大约 50%。
使用索引查询的过程是怎么样的,什么叫回表、覆盖索引?
对于如下表:
mysql> create table T (
ID int primary key,
k int NOT NULL DEFAULT 0,
s varchar(16) NOT NULL DEFAULT '',
index k(k))
engine=InnoDB;
insert into T values(100,1, 'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
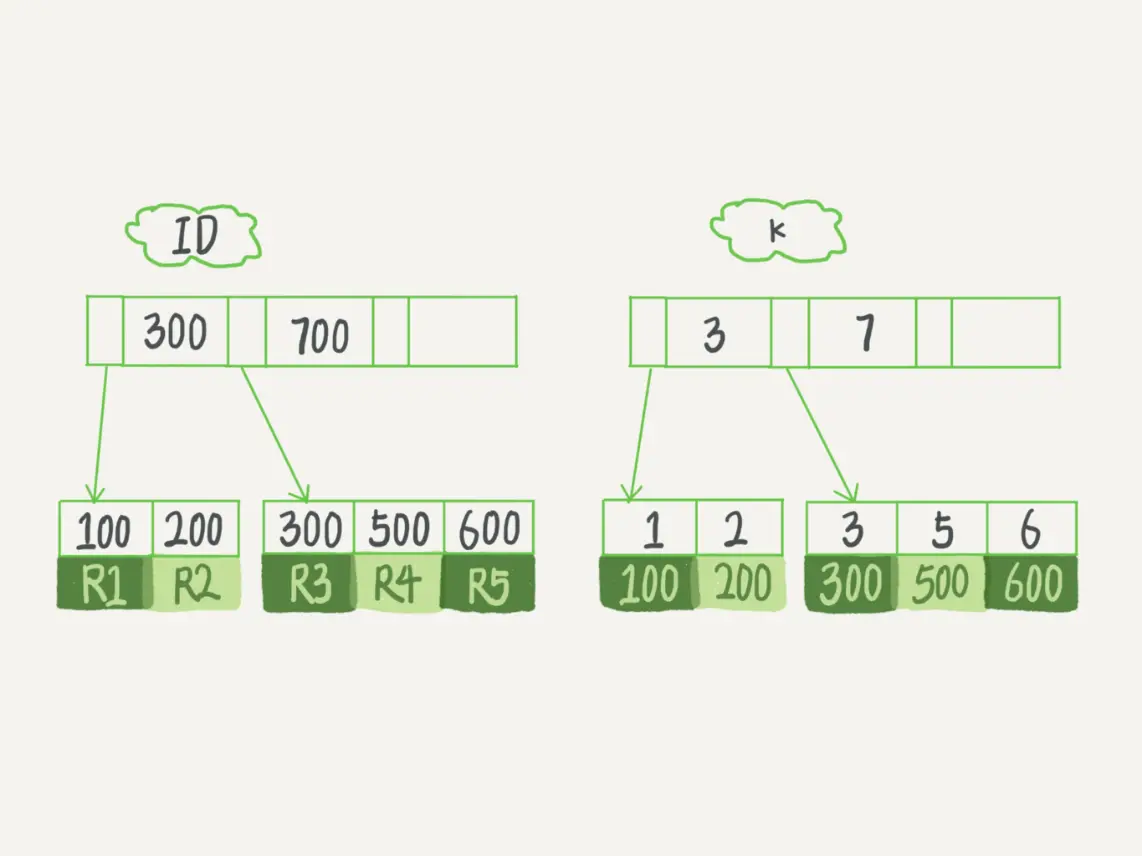
当执行select * from T where k between 3 and 5时,过程如下:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
可以看到,MySQL先在k索引树上查找满足条件的记录,拿到主键,然后再到主键索引树上去取整条记录。这个用主键去主键索引上取数据的操作就叫做回表。
回表的过程重新访问了主键索引,有没有什么办法可以避免回表?
如果将上面的查询语句改成select ID from T where k between 3 and 5,这时我们查询k索引树的时候,由于ID已经在k键索引上存在了,因此就不需要再进行回表操作。索引覆盖了我们的查询需求,称为覆盖索引。
什么叫最左前缀,索引下推
对于一个记录居民身份信息的表,其(name, age)索引如下:
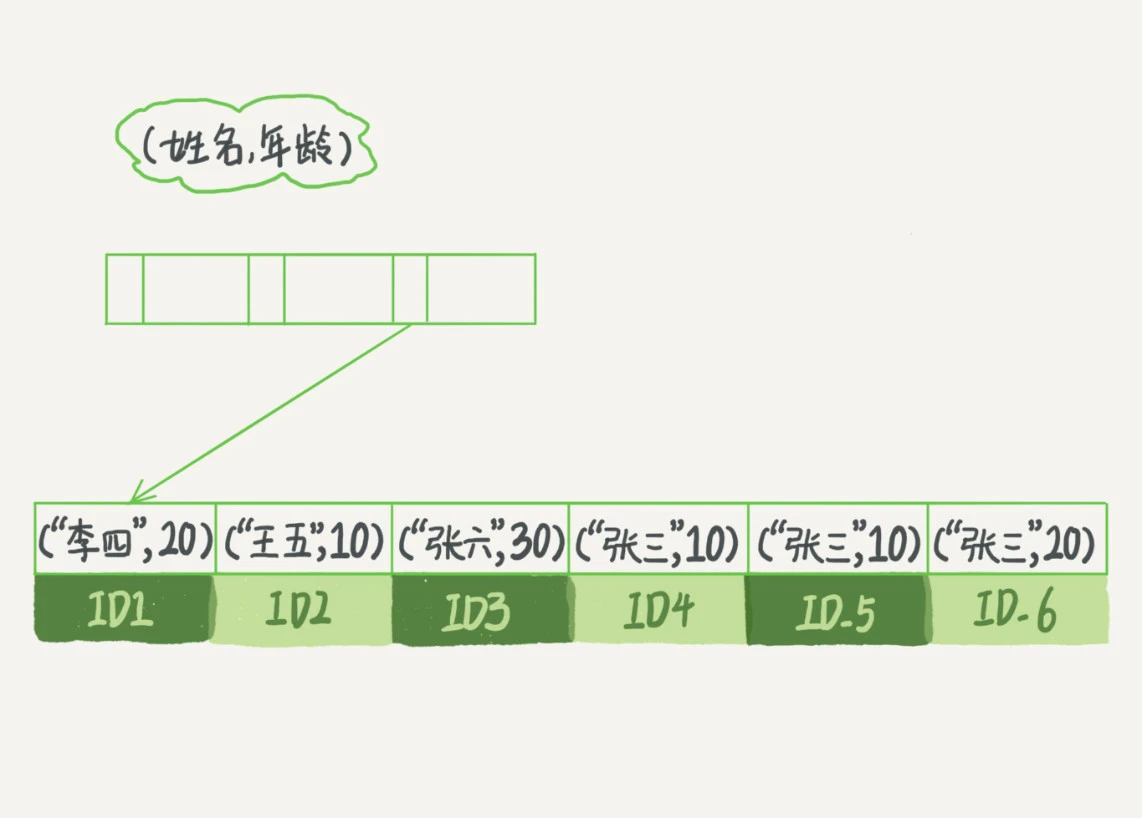
当我们想要在这张表上查询name=张三的记录时,可以通过索引快速定位到ID4,然后继续往后查找。类似的,当我们想要查找name like 张%的记录时,也可以利用这个索引快速定位到满足条件的第一个记录ID3.
可以看到,不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
对于如下语句:
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
在MySQL5.6之前,在(name, age)索引上找到符合name like '张%'的记录后,仍然需要根据索引上存储的主键去主索引上回表,待将整行数据全部取出后再进行判断。
但仔细观察可以发现,(name, age)联合索引上已经存在age字段,也就是说,对于age=10这个条件判断,我们完全不需要进行回表,只用当前索引上的数据就可以进行判断。这叫做索引下推
扫描行数是如何判断的?
当一个语句被分析完毕后,会由优化器来选择索引,目的是找出一个最优的执行方案,并用最小的代价去执行语句。其中,扫描行数是一个比较重要的判断标准。
MySQL 在真正开始执行语句之前,并不能精确地知道满足这个条件的记录有多少条,而只能根据统计信息来估算记录数。
这个统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”(cardinality)。也就是说,这个基数越大,索引的区分度越好。
可以使用show index方法,查看索引的基数。但,基数可能会不准确。
MySQL采用采样的统计的方法得到索引的基数。
为什么要采样统计呢?因为把整张表取出来一行行统计,虽然可以得到精确的结果,但是代价太高了,所以只能选择“采样统计”。
采样统计的时候,InnoDB 默认会选择 N 个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
而数据表是会持续更新的,索引统计信息也不会固定不变。所以,当变更的数据行数超过 1/M 的时候,会自动触发重新做一次索引统计。
在 MySQL 中,有两种存储索引统计的方式,可以通过设置参数innodb_stats_persistent 的值来选择:
- 设置为 on 的时候,表示统计信息会持久化存储。这时,默认的 N 是 20,M 是 10。
- 设置为 off 的时候,表示统计信息只存储在内存中。这时,默认的 N 是 8,M 是 16。
由于是采样统计,所以不管 N 是 20 还是 8,这个基数都是很容易不准的。
如何修正索引统计信息?
analyze table <table_name>;
对于字符串索引,有哪些优化方式
对于邮箱等字段,可以使用前缀索引。但使用前缀索引存在一个问题:即使前缀索引中已经包含了查询所需要的全部信息,但MySQL仍然要进行回表,因为系统并不确定前缀索引的定义是否截断了完整信息。也就是说,使用前缀索引就用不上覆盖索引对查询性能的优化了.
对于身份证号这种类型,可以使用倒序存储,这样可以更好的使用前缀索引。
还可以使用hash字段,在表上再创建一个整数字段,来保存字段的校验码,同时在这个字段上创建索引。